Share
「いつでも、どこでも」の実現に向けた 、AFEELAのAD /ADASアーキテクチャ

自動運転を実装した社会の実現に向けて、自動運転におけるクルマの知性を司るAD /ADASアーキテクチャの進歩は、もっとも大きなテーマのひとつとなっている。
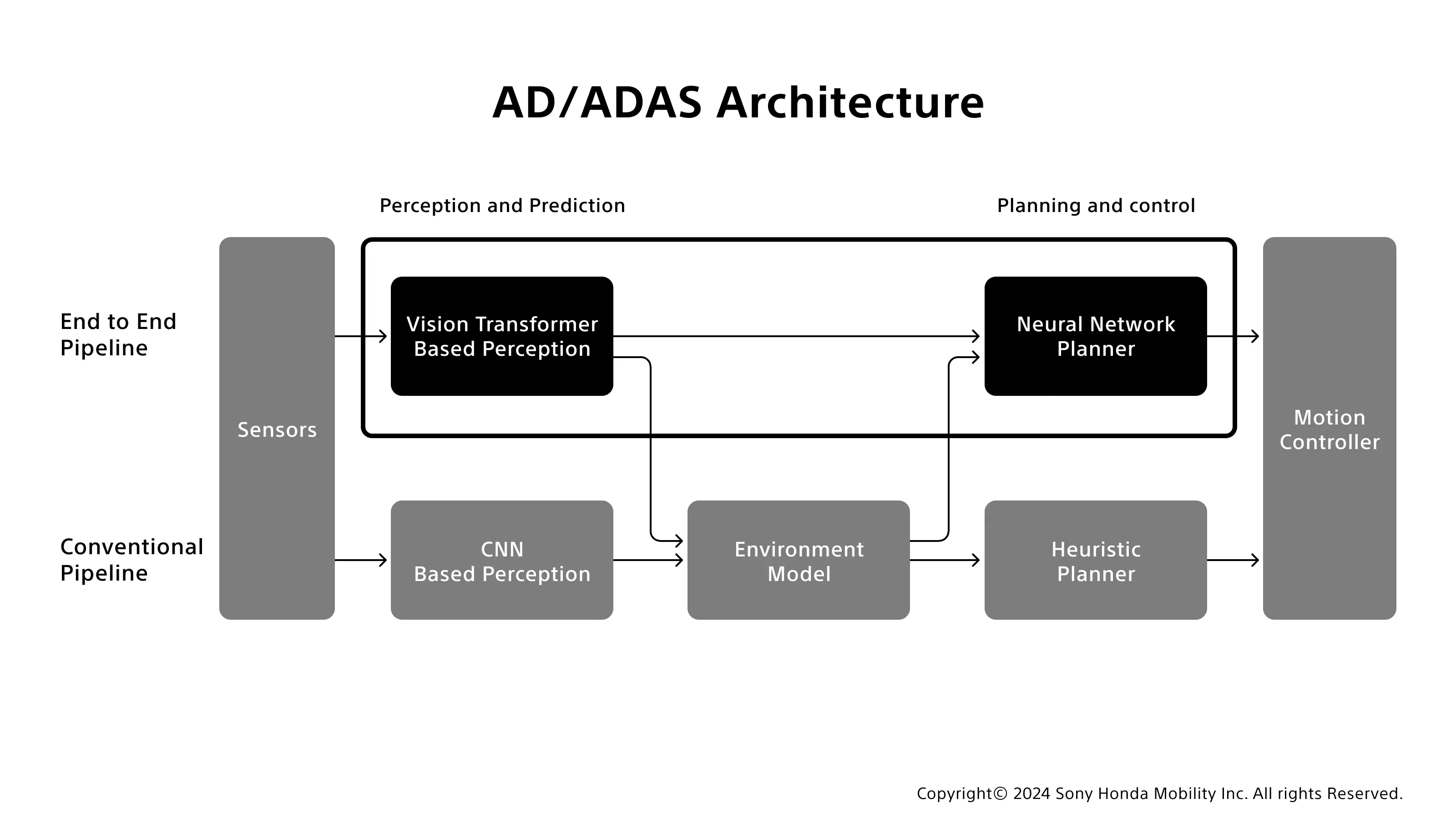
AFEELAのAD/ADASアーキテクチャ構想は、多様なセンサーから入力された情報をもとに外界を認識し、ルート計算のプランニング&コントロールまでの流れで求められる複雑なタスクを、「解析的/演算的」な手法ではなく「学習」をベースにした手法で、一括で解くことを目指している。「こうしたケースは減速/加速する」といったように、明確な判断基準のもと演算的にクルマの機能を制御するだけでなく、非常に複雑な判断を要する答えを導き出すことができる可能性が高い。AFEELAは、空間の認識を行う領域においても学習ベースの技術を採用しており、それが新しい画像分類モデルである「ViT(Vision Transformer)」だ。
コンテクスト型の画像分類モデル「ViT」
車両センサーから入力される情報を認知するための画像分類モデルにおける、現在の主流はCNNである。カメラで取得した画像情報に、矩形型の学習フィルタをかけることで認識対象の特徴量を局所的に抽出する、テクスチャ重視で演算効率に優れたモデルだ。
一方ViTは、複数センサ(カメラ、LiDAR、RADAR)の入力に対しても同様に、各モーダルの情報をベクトル化して扱うことで関係性をとらえて認識をする。単語ではなく、文をベクトル化して前後の文脈で理解をする言語モデルをベースにした、コンテクスト重視の画像分類モデルといえる。
例えば、人やクルマの検知を、対象物のテクスチャといった見た目の情報だけではなく、周囲のシーン構造なども考慮しているため、CNNでは難しい夜や悪天候であっても高い性能を実現できることがわかってきている。また、人やクルマなどの属性だけではなく、位置や姿勢といった情報も推定している。

「いつでも、どこでも」を実現する
将来的にクルマが自律した走行で自在に移動する事は、人々の移動の可能性の拡張につながる。乗り込めば何もせずとも目的地まで勝手に移動してくれる事を、世界中の多くの人々が一度は夢見たことだろう。いわゆるレベル5の「完全自動運転」だ。AFEELAもまたその夢を追いかけているが、技術的ハードルはもちろん、国際的な協調・協力が必要となる。それらを背景に技術的な革新のため、AFEELAのAD/ADASが将来に向けて掲げるコンセプトは「いつでも、どこでも」である。時間や天候に関わらず(いつでも)、自動走行用のマップがない場所でも(どこでも)、走行に必要な周辺環境の情報(物体、レーン、走行路)をセンサー情報から高い精度でロバストに認識できる技術を目指している。例えば、車線は劣化、周辺車両による隠れ、天候、そもそも白線がないなどの理由で局所的な情報では検知できないケースが多くある。このようなケースでは、局所的な見え方の情報だけでは解くことができず、路面構造や周辺車両の位置と動きなどシーンの文脈から推定する必要がある。シーン全体の文脈の利用に強みを持つViTは有効なアプローチと言えるのだ。
一方で、性能面での課題も存在する。例えば、住宅街の細い路地といったラストワンマイルなど、地図データが不足している場所で適切に認識・判断することは難しい。また、交差点はレーンがないため、マップデータなしに自動運転で曲がることも難しいのである。また、関係性の学習や処理に必要なデータが膨大であることも、課題として挙げられるだろう。
ViTはCNNと異なり局所的な帰納バイアスを持たない。そのため高い汎化性を持つ一方、学習には多くのデータを必要とする。この特性ゆえに学習すればするほど高い汎化性(いつでもどこでも高い性能)を持つことができる。
従来は周辺環境の構造や車両の動きをモデル化することで、解析的に最もリスクが少ない経路を求める手法が主流だった。しかし、市街地一般道の人やバイクなどは挙動が複雑でモデル化が難しく、リスクを解析的に求めることが困難になる。 学習型のニューラルネット型プランニング技術を採用することで、データドリブンで周辺のリスクのモデルを獲得し一般道でもリスクのない経路を判断する。学習型のルートプランナーは学習データが増えるほどに自然で安全な経路判断が可能となるため、アーキテクチャとデータ拡充についてさらにスタディしていく。
“コードを書きたくなる”自動運転を見据、AIを活用したドライビングシミュレーター
「見えない未来」を見据えて
ViTの認知精度のさらなる向上を行い、一般公道で走行可能なレベルを実現していくと同時に、より未来のことも想像する必要がある。現在の自動運転は、センサーなどから入力された情報に対して、いかにクルマが正しく認識するかに主眼を置いて各社が技術開発を進めている。
クルマの画像認識が実用に足るレベルに到達したら、より高い精度での認識や判断の処理速度の向上など、ViTの開発の意義は、こうした「さらにその先」を想像するための知見を、着実に積み重ねていることにもある。「いつでも、どこでも」の本当の意味での実現は、こうした未来をプロトタイプしていきながら、技術開発に挑戦し続けた先にある。
Interviewer: Takuya Wada
Writer: Asuka Kawanabe
Related
