Share
AI-Based Trajectory Inference Powering AFEELA’s Autonomous Driving

We are Takehiko Hanada and Rintaro Yamaguchi from the Autonomous System Development Division at Sony Honda Mobility, where we develop trajectory inference for autonomous driving. Trajectory inference is the cornerstone of autonomous driving. It involves processing inputs from diverse sensors to understand the surrounding environment, deciding how the vehicle should behave, and formulating a specific motion plan. In this article, we introduce our approach through three key lenses: Trajectory Inference, Simulation, and Machine Learning Operations (MLOps).
Advancing Trajectory Inference
By combining State-of-the-Art (SOTA) technology with proprietary modules, we expand our ability to handle complex traffic scenarios. We resolved feature interference via automated detection, enabling seamless functional expansion without performance degradation.
Precision Evaluation via Simulation
Using simulations, we automated the evaluation of multi-faceted metrics as acceleration and curvature. This enables faster identification of bottlenecks and supports the generation of high-precision, physically consistent trajectories.
Accelerating Development Cycles
By integrating MLOps to automate the flow from training to evaluation, we reduced process time to less than 1/10 of its original length. Parallel Data Operations (DataOps) initiatives also cut the time required to generate training by more than half.
Characteristics of Trajectory Inference
Developing trajectory inference systems presents three fundamental challenges: multi-functionality, the application of state-of-the-art (SOTA) technology, and the risk of functional interference or degradation within a single output.
Multi-functionality and SOTA application trajectory inference must handle a vast array of driving scenarios. This ranges from fundamental behavior (e.g., smoothly following of a lead vehicle, lane keeping, and stopping at stop lines) to complex decision-making in dense traffic (e.g., determining whether to yield or proceed during a highway merge). Furthermore, commercial vehicles add another layer of complexity. Features such as “reaching a destination” and “following navigation routes” are essential in real-life products, yet often absent from academic research. As a result, many of these capabilities must be designed, implemented, and validated internally. To address this, we continuously test and refine unique innovations to model architectures, input methods, and loss functions, to expand our system’s capabilities to handle real-world driving demands.

Unlike object recognition, where inputs and outputs often align in a near one-to-one relationship, trajectory inference compresses all driving intent into a single output: the vehicle’s path. This creates a unique challenge. When a new capability is introduced, it can unintentionally interfere with existing ones. For example, improving performance at stop lines may degrade stability when following a lead vehicle. We refer to this phenomenon as “degradation.” To manage this risk, we utilize a development methodology to emphasize rapid iteration and early detection. We visualize the correlation between degradation and training data, identify root causes through thorough internal model analysis, and automate the early detection of degradation via simulation. By accelerating the trial-and-error cycle, we can identify issues before they propagate downstream.
Trajectory Quality and Evaluation via Simulation

At first glance a generated trajectory plan may appear smooth in terms of shape and velocity. But closer inspection over a smaller time range often reveals unrealistic acceleration or curvature that would fail on a physical vehicle. Furthermore, as mentioned previously, functional interference can often lead to performance degradation. Simulation allows us to detect these issues early and cost-effectively.
Testing with real vehicles is time-consuming and expensive. Our simulation environment allows us to replicate specific scenarios (e.g., car following, stopping at lines, or pedestrian crossings) to evaluate the inferred trajectory instantly and in detail. We assess simulation results using metrics required to complete a scenario (e.g., deviation from target speed/lane, arrival rate, and collision rate), as well as physical feasibility metrics (e.g., acceleration and curvature). Evaluation axes are customized for different scenarios, such as cruising on a straight road, navigating intersections, or driving in traffic.
Driving High-Speed Development and Improvement
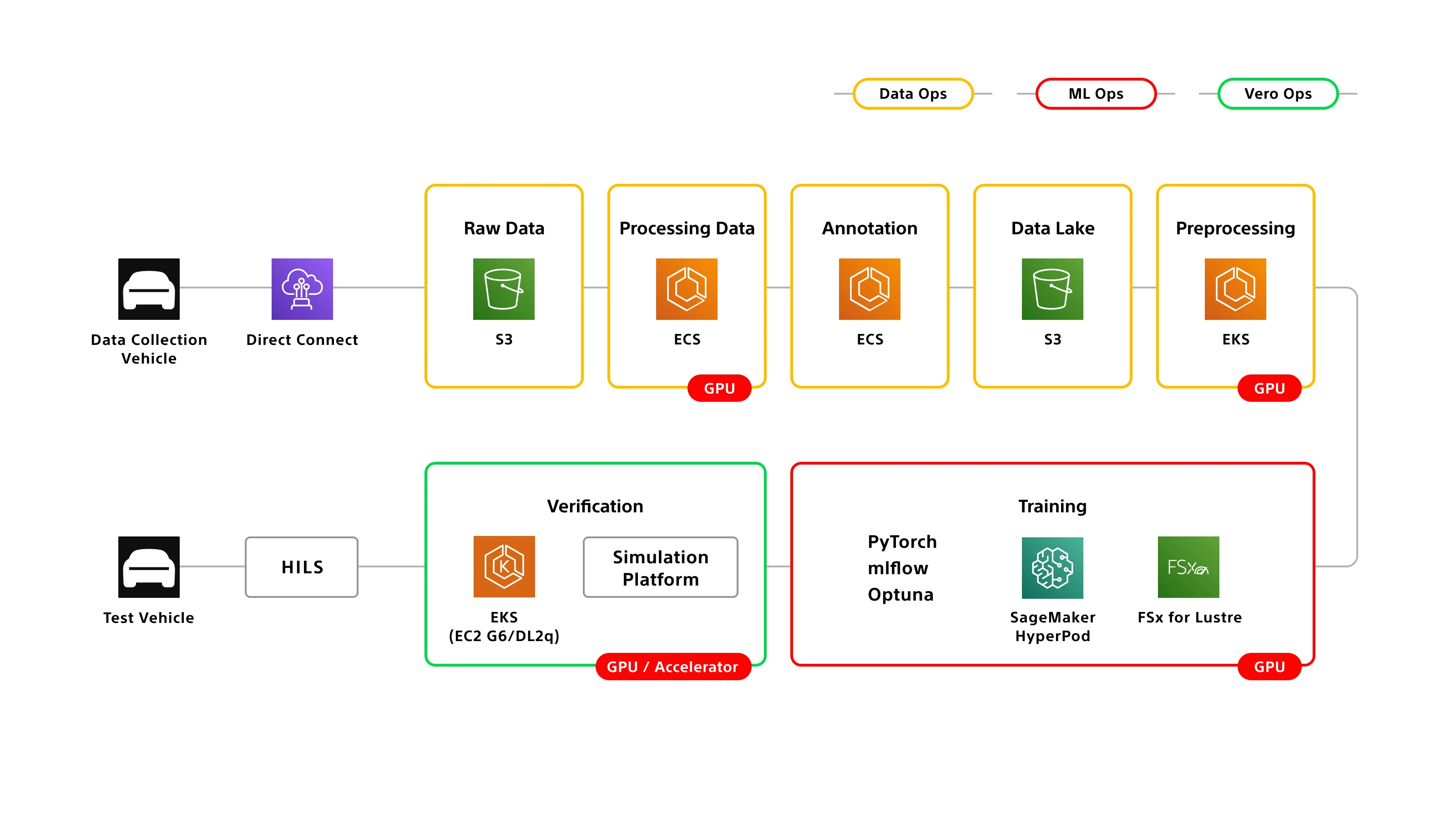
From the beginning, we prioritized automating the development process itself. To maximize efficiency, we built robust MLOps and DataOps pipelines to automate training data generation, AI model training, and evaluation.
Our training pipeline is fully automated. When an engineer modifies the training code on GitHub, training starts automatically. Once complete, the system launches simulations, measures metrics, aggregates data, and presents a final score, without manual intervention. This frees our engineers from mundane tasks, allowing them to focus on core development: improving code, analyzing data, and interpreting results. Automation has reduced the cycle time from training to evaluation to less than one-tenth of what it was at the start of the project.
On the data side, we have built a pipeline capable of periodically regenerating all training data. Since trajectory inference depends on the output of the perception layer, we feed stored sensor and CAN data from our collection vehicles into the latest software and perception models to create up-to-date training datasets. As perception technology evolves rapidly, regenerating data ensures that our trajectory models are always trained on the most current and accurate inputs available. By eliminating manual steps and executing processes in parallel, we have reduced the time required to generate training data by more than half. Our cloud-based architecture allows us to scale out and increase node capacity as needed, ensuring lead times remain stable even as data volume grows.
The Thrill of Bringing Theory to Life

At Sony Honda Mobility, we are developing autonomous driving technology with our own hands to create what we truly want to see in the world. It is rare in this industry to find an organization that pursues both SOTA technology and is directly linked to mass production. Being able to push forward into unprecedented technical territory based on our own ideas is both a massive challenge and accomplishment.
There is joy in seeing a car move exactly as we intended. Seeing an idea evolve from a desk sketch into the physical world—and knowing it will eventually reach customers—is our ultimate motivation. The sense of achievement we feel when we bridge the gap between simulation and reality, and the car moves exactly as intended after complex tuning, is truly irreplaceable. It is in this moment—when theory becomes motion—that we are reminded why we build.
The statements and information contained here are based on development stage data.
Related